A quiet-room demo is not a clinical workflow. Voice-first AI can look effortless in a lab and still fail the moment it meets a real round: hallway noise, interruptions, accents, half-finished sentences, privacy constraints, and a clinician who has no time to babysit the interface.
That is the bar we are designing against at OmegaX. The goal is not to make speech recognition feel impressive. The goal is to make clinical documentation and clinical logging possible while the clinician is still moving.
The product constraint
Clinicians do not need another screen competing for attention. During rounds, the work is examination, conversation, decision-making, and handoff. Documentation has to fit around that work without pulling the clinician out of it.
That is why we went voice-first. Not voice-only, and not voice as a novelty layer on top of a typing workflow. Voice is the primary capture mode because it is the only interface that can work when hands, eyes, and attention are already occupied.
The fallback still matters. A trustworthy clinical product needs fast correction, clear review, and a typed path when the model misses something. But the default loop has to start with speech.
The loop we shipped
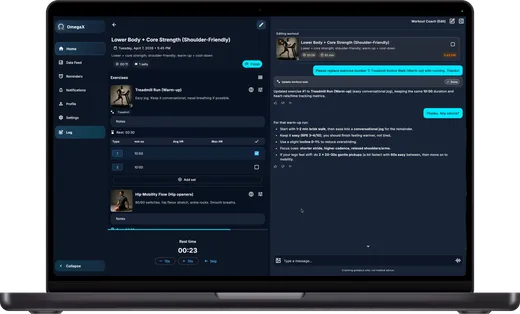
The first version of the workflow was intentionally simple:
- The clinician speaks into OmegaX during or right after an encounter.
- On-device voice activity detection separates speech from silence and background audio.
- Streaming ASR turns each usable segment into text.
- A second model converts the transcript into structured clinical fields.
- The clinician reviews, corrects, and signs before anything becomes part of the record.
The skeleton looked like this:
async function streamEncounter(stream: MediaStream) {
const session = new VoiceSession(stream);
for await (const utterance of session.utterances()) {
const transcript = await asr.transcribe(utterance);
await encounter.append(transcript);
const summary = await extractor.toStructuredSummary(encounter.current());
ui.renderDraft(summary);
}
}That loop is straightforward on paper. In practice, every step hides product decisions that matter as much as the model choice.
What real rounds taught us
Latency is felt through feedback
We first treated latency as an engineering problem: smaller models, tighter streaming, faster inference. Those helped, but the larger shift was product design.
Clinicians did not need a perfect live transcript racing across the screen. They needed evidence that the system was listening, plus a structured draft that caught up at natural pauses. The experience felt faster once the interface showed progress in the shape of the final artifact, not just raw words.
Noise robustness beats benchmark accuracy
In a quiet room, modern ASR systems can all look competent. Real clinical spaces are not quiet rooms. Corridors, alarms, masks, side conversations, and device audio all change the product.
For clinical documentation, the useful question is not only "How accurate is the model?" It is "What happens when the acoustic environment is bad and the user cannot stop to fix the setup?"
That pushed us toward stronger front-end audio handling, conservative segmentation, and clearer uncertainty states. A model that admits uncertainty in the right place is more usable than one that confidently writes the wrong thing.
Trust comes from correction
Accuracy matters, but trust is built at the correction layer. Clinicians will tolerate some transcription error if the error is visible, localized, and easy to fix. They will not tolerate a system that hides uncertainty or turns correction into another documentation burden.
The adoption lever was not a grand AI moment. It was one-gesture repair: tap the field, speak or type the correction, keep moving.
The artifact matters more than the transcript
A transcript is a raw material. The clinician does not want a diary of the encounter; they want a usable clinical artifact: problems, assessment, plan, follow-up, and anything that should be handed off.
That changed how we thought about the interface. The center of gravity moved away from "watch the transcript stream" and toward "review the structured draft." The transcript still exists for traceability, but it should not be the main event.
What changes next
The next version moves further toward ambient clinical workflow, but with the same discipline: no fake autonomy, no invisible medical decision-making, and no record changes without review.
The main upgrades are:
- On-device first capture, so privacy and offline behavior improve before the network is involved.
- Speaker diarization, so clinician speech and patient speech are separated before structured extraction.
- Better uncertainty display, so the review UI shows what needs attention instead of pretending everything is equally reliable.
- Faster correction, so clinical logging stays lighter than typing from scratch.
Voice-first AI is not a magic interface. It is a very demanding one. But when it works in the messy middle of clinical work, it removes the exact friction that makes most documentation tools fail.